Systematic AI Agent Evaluation with Strands Evals
Strands Evals offers a comprehensive framework for systematic AI agent evaluation. Leverage LLM-based evaluators, user simulation, and automated test generation for robust agent quality assurance.


Strands Evals offers a comprehensive framework for systematic AI agent evaluation. Leverage LLM-based evaluators, user simulation, and automated test generation for robust agent quality assurance.

Revolutionize GenAI evaluation on SageMaker with Amazon Nova’s rubric-based LLM judge. Dynamically generate criteria, get transparent scores & justifications for data-driven model improvements.

Learn how to select the right LLM with AWS’s 360-Eval framework. This guide details multi-metric evaluation, covering accuracy, cost, and latency for data-driven decisions.
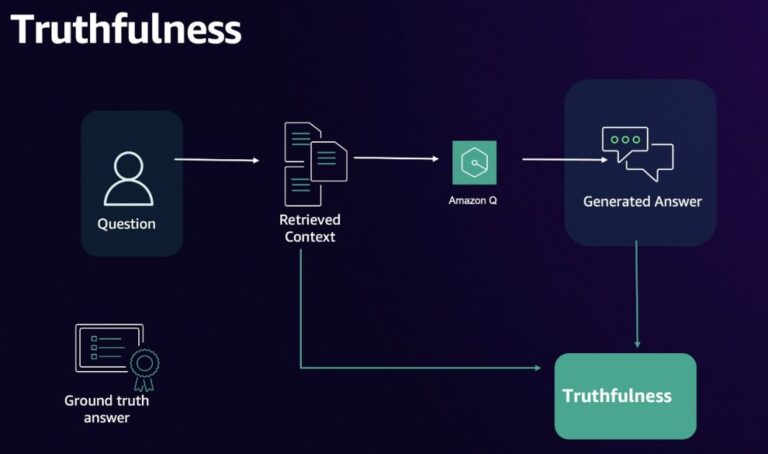
Evaluate Amazon Q Business accuracy with AWS’s new framework. Learn about key metrics, two solution architectures (comprehensive & lightweight), and strategies to improve your RAG application’s performance.
The information provided on this website is provided for entertainment purposes only. We make no representations or warranties, expressed or implied, about the information. This includes its completeness, accuracy, adequacy, legality, usefulness, reliability, suitability, and availability. We also make no claims about anything else. Any reliance you place on the information is strictly your own responsibility. We accept payment from advertisers and sponsors with relevant ads. We may recommend products on our website and get paid to advertise them. You can find additional terms in the terms of use.