Adobe Boosts Developer Productivity with Amazon Bedrock
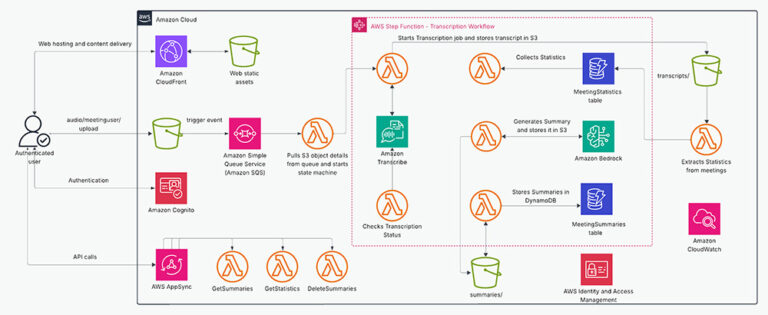
Adobe significantly enhanced its internal developer support system, “Unified Support,” by leveraging Amazon Bedrock Knowledge Bases and the Vector Engine for Amazon OpenSearch Serverless. This solution aimed to improve the accuracy of document retrieval and enable scalable, automated deployment for thousands of developers. The core of the system involves indexing Adobe's internal documentation (wiki pages, guidelines, troubleshooting guides) using Amazon Bedrock. Data is ingested from Amazon S3, chunked, vectorized using Amazon Titan V2, and stored in the Amazon OpenSearch Serverless vector database. When a developer queries the system, their question is vectorized, compared to indexed vectors, and the most similar documents are retrieved and presented. A key feature is metadata filtering, allowing developers to refine searches based on criteria like domain, year, or type, improving the relevance of results. Adobe achieved a 20% increase in retrieval accuracy. The implementation utilized a fixed-size 400-token chunking strategy for optimal performance, outperforming other methods like semantic and hierarchical chunking in experiments using Ragas for evaluation based on document relevance and Mean Reciprocal Rank (MRR). This solution demonstrates a powerful application of Amazon Bedrock for building large-scale, internal knowledge bases, improving developer experience and reducing support costs. While the solution is tailored to Adobe's specific needs, the architecture and methodology could be adapted for other organizations seeking to improve internal knowledge management and developer productivity. The system's success highlights the potential of vector databases and generative AI for efficient knowledge retrieval. However, potential drawbacks could include the ongoing costs associated with using AWS services and the need for careful data preparation and indexing to ensure optimal performance.
The AI automation Adobe has implemented through Amazon Bedrock enables developers to streamline workflows and accelerate application development processes significantly.
While chatgpt automation adobe solutions have gained popularity, Adobe's partnership with Amazon Bedrock offers enterprise-grade AI capabilities specifically designed for developer workflows.