Amazon SageMaker HyperPod: Faster Generative AI Model Deployments
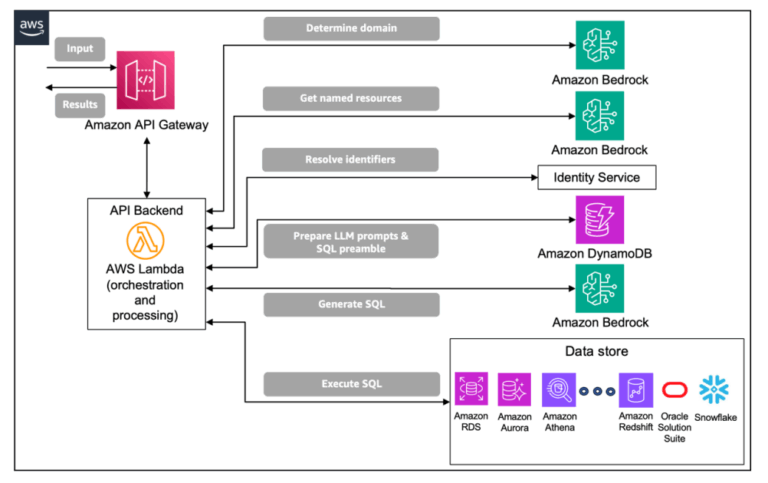
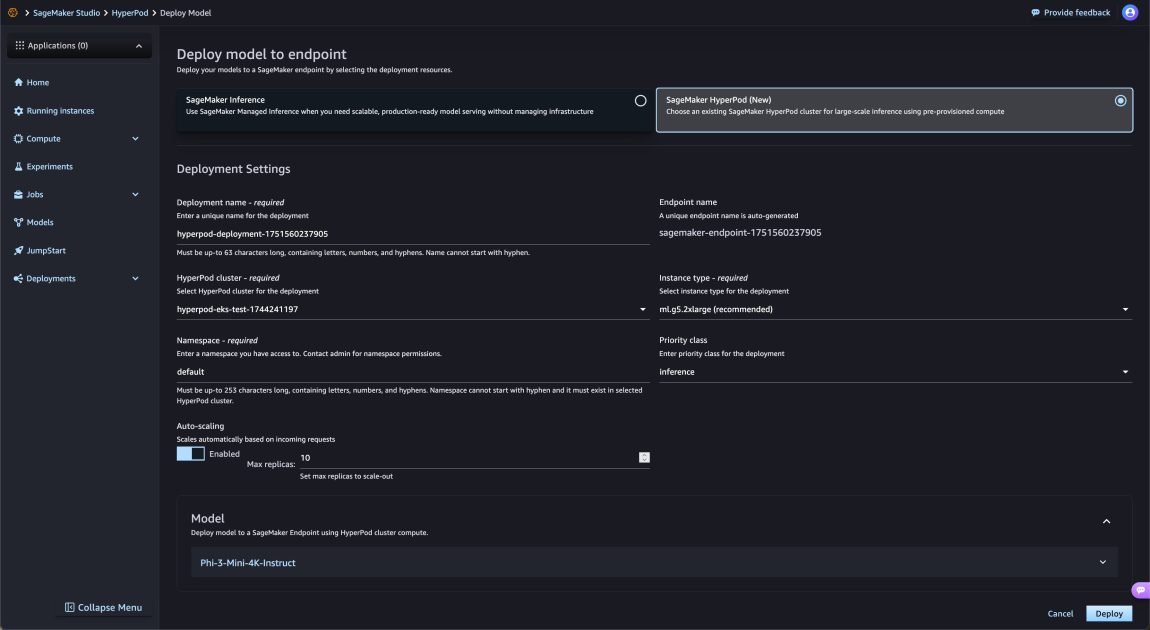
Amazon SageMaker HyperPod accelerates the generative AI model development lifecycle by enabling faster model deployments. This enhanced service now supports deploying foundation models (FMs) from SageMaker JumpStart, along with custom or fine-tuned models from Amazon S3 or Amazon FSx. The key benefit is the ability to train, fine-tune, and deploy models using the same HyperPod compute resources, maximizing resource utilization and reducing time to market. HyperPod offers resilient, high-performance infrastructure optimized for large-scale model training and tuning, addressing challenges faced by organizations using Kubernetes for foundation model inference at scale. New features include one-click deployment from SageMaker JumpStart (supporting over 400 models), seamless deployment from S3 or FSx, flexible deployment options (kubectl, HyperPod CLI, SageMaker Python SDK), dynamic scaling based on demand (CloudWatch, Prometheus, KEDA), efficient resource management with HyperPod Task Governance, and integration with SageMaker endpoints. The system provides comprehensive observability, offering platform-level and inference-specific metrics. Different user personas are catered to, including administrators, data scientists, and MLOps engineers. The architecture involves new operators managing the model lifecycle, provisioning Application Load Balancers (ALBs), and generating TLS certificates. Models can be deployed via SageMaker JumpStart, S3, or FSx, with various deployment methods (kubectl, HyperPod CLI, Python SDK) available. Inference can be performed via SageMaker endpoints or directly using the ALB. Autoscaling is supported through the HyperPod inference operator or KEDA, handling traffic spikes efficiently. Task governance optimizes resource utilization through priority-based scheduling using Kueue. While offering significant advantages in speed and efficiency, users should be aware of the potential costs associated with running instances in the cluster and manage scaling appropriately. Overall, HyperPod aims to streamline the entire generative AI workflow, from training to deployment and scaling.
Amazon's ai automation sagemaker platform revolutionizes machine learning workflows by streamlining the entire process from model training to production deployment.
Organizations seeking chatgpt automation sagemaker solutions can now leverage HyperPod's enhanced infrastructure to streamline their AI model deployment workflows.