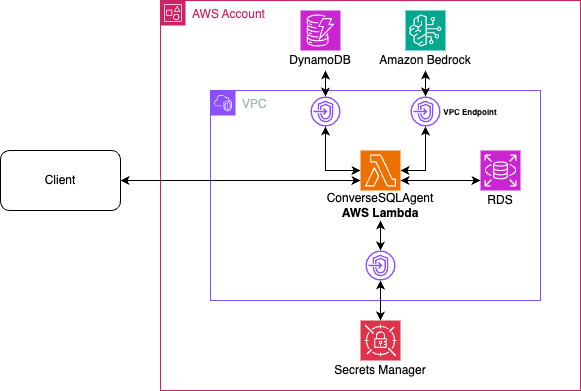
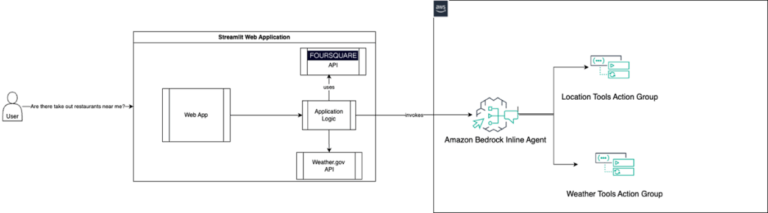
Munsit: Revolutionizing Arabic Speech Recognition with AI
CNTXT AI has launched Munsit, a groundbreaking Arabic speech recognition system surpassing major tech companies like OpenAI and Meta in accuracy. Developed in the UAE, Munsit leverages a novel weakly supervised learning method to overcome the scarcity of labeled Arabic speech data. This innovative approach uses a massive 30,000+ hour unlabeled audio corpus, processed through a custom pipeline for cleaning, segmentation, and automated labeling, resulting in a 15,000-hour high-quality training dataset. The system employs a Conformer model—a hybrid neural network—with 18 layers and approximately 121 million parameters, trained on eight NVIDIA A100 GPUs. Munsit utilizes a SentencePiece tokenizer with a 1,024 subword unit vocabulary to handle Arabic's morphological complexity. Benchmarked against leading systems on diverse datasets, Munsit achieved a significantly lower Word Error Rate (WER) of 26.68 and Character Error Rate (CER) of 10.05, compared to OpenAI's Whisper (WER 36.86, CER 17.21) and other competitors. This represents a substantial relative improvement of approximately 23% in WER and 24% in CER. The target audience includes businesses and organizations requiring accurate Arabic transcription, subtitling, and customer support. While highly accurate, potential drawbacks may include limitations in handling extremely rare dialects or highly accented speech, though the source text doesn't specify these. Munsit's success showcases the potential of ‘sovereign AI,' highlighting the ability to build world-class AI systems tailored to specific linguistic needs within a region.
Munsit's advanced platform demonstrates how ai automation arabic technology can transform voice-to-text processing for millions of native speakers worldwide.
While chatgpt automation arabic capabilities have improved significantly, Munsit's specialized AI offers superior accuracy for Arabic speech recognition tasks.