SageMaker HyperPod: Blazing Fast Model Training with Tiered Checkpointing
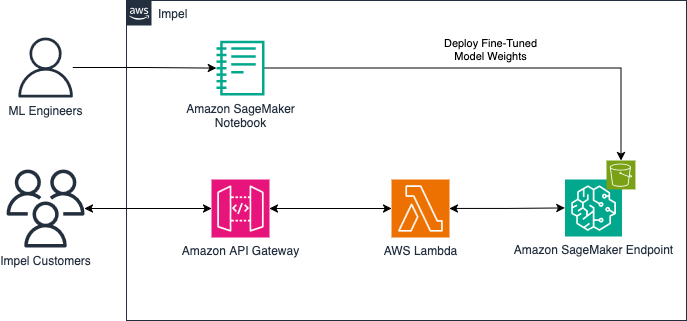
Amazon SageMaker HyperPod introduces managed tiered checkpointing to drastically accelerate large-scale model training. This feature addresses the cost-performance trade-off inherent in frequent checkpointing for resilience against common failures in distributed training environments (like those reported by Meta, experiencing failures every 3 hours). Managed tiered checkpointing leverages CPU memory for high-speed checkpoint storage, with automatic data replication across nodes for redundancy. Checkpoints are asynchronously copied to persistent storage like Amazon S3, ensuring data durability. The solution integrates seamlessly with PyTorch Distributed Checkpointing (DCP), minimizing disruption to training. It’s designed for large-scale distributed training clusters, tested on setups ranging from hundreds to over 15,000 GPUs, achieving checkpoint saves within seconds. The system automatically handles node failures, enabling training to resume quickly. Users can configure checkpoint frequency and retention policies for both in-memory and persistent storage tiers. Implementation involves installing the `amzn-sagemaker-checkpointing` library, configuring a namespace, and adding a few lines of code to the training loop. The solution is free and uses existing SageMaker HyperPod infrastructure. Key benefits include faster recovery times, reduced storage costs, and simplified checkpoint management. The target audience includes organizations training large language models and other computationally intensive AI models needing high performance and resilience.
SageMaker HyperPod revolutionizes ai automation training workflows by dramatically reducing checkpoint overhead and accelerating machine learning model development cycles.
Organizations implementing chatgpt automation training workflows can significantly reduce computational costs and training time using SageMaker HyperPod’s advanced checkpointing capabilities.