VLM2Vec-V2: Unified Multimodal Embedding for Images, Videos & Documents
VLM2Vec-V2: A unified framework for multimodal embedding learning across images, videos, and documents. Outperforms existing models on various benchmarks.

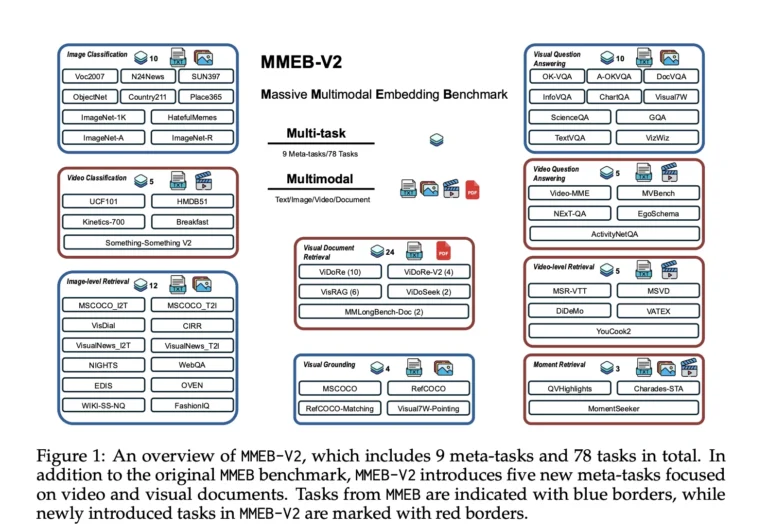
VLM2Vec-V2: A unified framework for multimodal embedding learning across images, videos, and documents. Outperforms existing models on various benchmarks.
The information provided on this website is provided for entertainment purposes only. We make no representations or warranties, expressed or implied, about the information. This includes its completeness, accuracy, adequacy, legality, usefulness, reliability, suitability, and availability. We also make no claims about anything else. Any reliance you place on the information is strictly your own responsibility. We accept payment from advertisers and sponsors with relevant ads. We may recommend products on our website and get paid to advertise them. You can find additional terms in the terms of use.