
VLM2Vec-V2: Unified Multimodal Embedding for Images, Videos & Documents
Salesforce Research, UC Santa Barbara, University of Waterloo, and Tsinghua University introduce VLM2Vec-V2, a groundbreaking computer vision framework for multimodal embedding learning. This model addresses the limitations of existing embedding models, which primarily focus on images and lack the ability to handle videos and visual documents effectively. VLM2Vec-V2 uses Qwen2-VL as its backbone, leveraging its advanced features like Naive Dynamic Resolution and Multimodal Rotary Position Embedding for efficient multimodal processing. A key innovation is its flexible data sampling pipeline, employing on-the-fly batch mixing and interleaved sub-batching to ensure stable contrastive learning across diverse data sources.
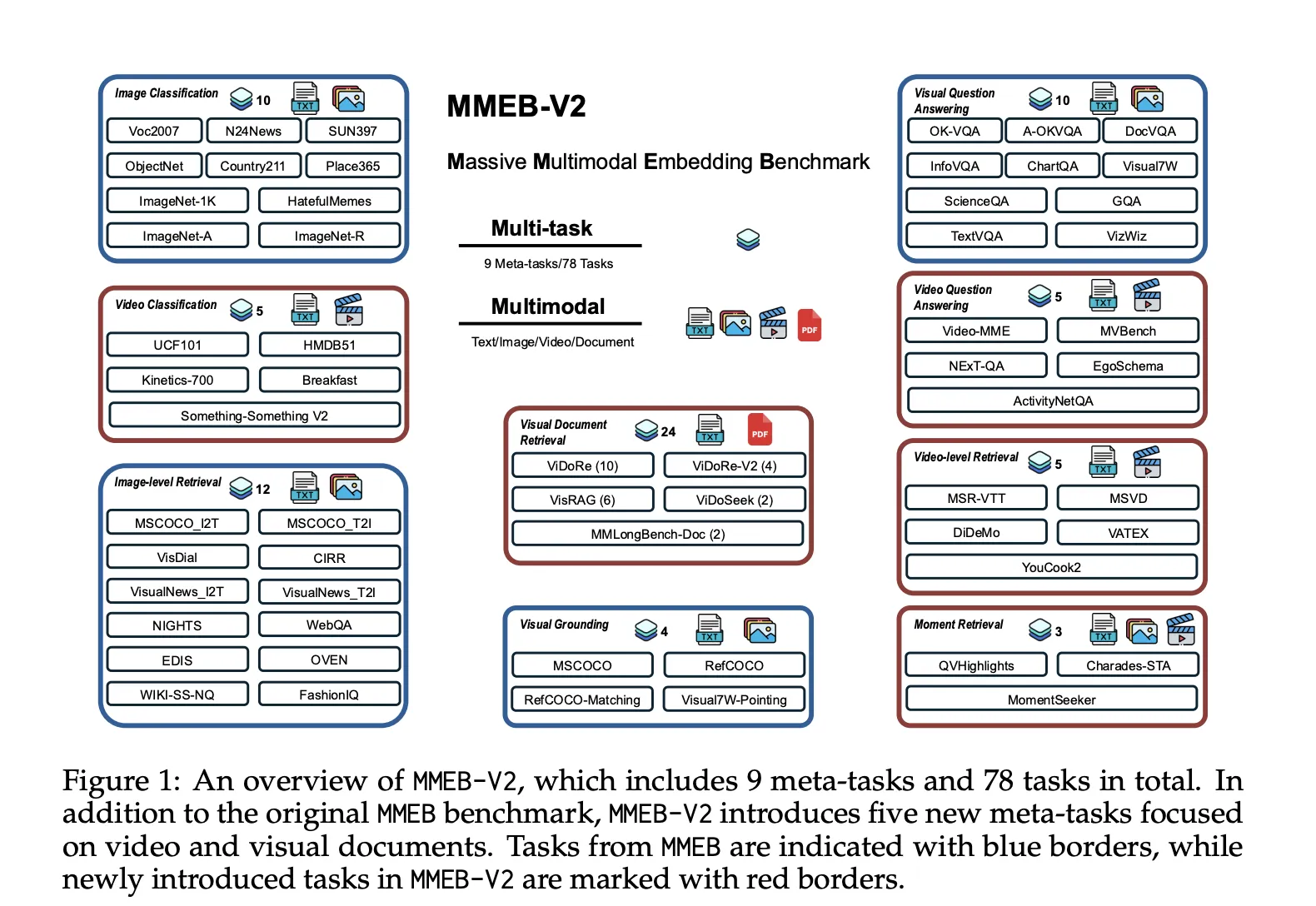
The model’s effectiveness is demonstrated on the newly developed MMEB-V2 benchmark, which includes five new task types encompassing visual document retrieval, video retrieval, temporal grounding, video classification, and video question answering, alongside existing image benchmarks. VLM2Vec-V2 achieves a remarkable 58.0 average score across 78 datasets, outperforming baselines like GME and LamRA. While excelling in image and video tasks (despite limited video data training), it shows some lag behind specialized models in visual document retrieval. Its 2B parameter size, compared to VLM2Vec-7B, showcases efficient performance.
VLM2Vec-V2’s target audience includes researchers and developers in computer vision and multimodal learning. Its unified framework offers scalability and flexibility for various applications, including improved search functionalities across articles, websites, and YouTube videos. However, potential drawbacks include its relatively smaller dataset for video training and the need for further development in visual document retrieval to match specialized models. The model’s architecture and its performance across a wide range of modalities make it a significant advancement in multimodal embedding learning.
VLM2Vec-V2 represents a significant advancement in ai automation embedding technology, enabling seamless processing of diverse multimedia content types.
VLM2Vec-V2 advances beyond current chatgpt automation multimodal approaches by creating more sophisticated unified embeddings for diverse content types.






